| qgis-0001-quebec-layers.png | ||
| qgis-0002-composer.png | ||
| README.md | ||
{kind=link}
{kind=link}
Informatique et politique
Voici une présentation que je prépare pour mes collègues de travail de Desjardins. Son contenu est de nature publique, alors je me permets de partager le tout ici pour le grand public.
Je vais présenter un aspect qui provient de mon vécu de bénévole dans une organisation politique: un coffre à outils qui permet de faire beaucoup avec peu de moyens financiers, et qui permet à plusieurs bénévoles dans des environnements de travail hétérogènes de pouvoir collaborer.
L'importance du logiciel libre pour la production et la gestion de contenu
Pour produire de nombreuses images sur le même modèle, mais en utilisant une base de données pour ajouter des éléments de personnalisation, j'ai choisi d'utiliser le format vectoriel. En utilisant le logiciel Inkscape, je construit un gabarit qui est sauvegardé au format SVG. Ensuite, à l'aide du module xml.dom.minidom de Python, on peut manipuler les valeurs des attributs pour personnaliser le fichier.
tspan_svg_field = doc.getElementsByTagName('tspan')
tspan_svg_field[0].childNodes[0].nodeValue = "dans "+candidat_dict['CIRC_NC']
tspan_svg_field[1].childNodes[0].nodeValue = candidat_json['candidat']['prenom_candidat']+' '+candidat_json['candidat']['nom_candidat']
image_svg_field = doc.getElementsByTagName('image')
image_svg_field[1].attributes["xlink:href"].value = cropped_photo_path
image_svg_field[0].attributes["xlink:href"].value = 'logo_pcq_bilingue.png'
candidat_svg_file = open(candidat_svg_path, "w")
candidat_svg_file.write(doc.toprettyxml())
candidat_svg_file.close()
Enfin, avec cairosvg, on peut générer des images PNG prètes pour le web.
svg2png(url=candidat_svg_path,write_to=candidat_png_path)
Une brochette de packages Python
import pandas as pd
from types import *
import cv2 as cv #Opencv
from PIL import Image #Image from PIL
import glob
import os
import numpy
import xml.dom.minidom
from cairosvg import svg2png
import json
from rauth import OAuth2Service
import base64
import datetime
import markdown
from pytz import timezone
import sys
from slugify import slugify
from IPython import display
Envoi de courriels massifs
À quelques occasions, je devais envoyer des courriels massifs, mais personnalisés, notamment pour la création de comptes utilisateurs dans nos divers outils de communications.
Pour ce faire, j'ai construit un petit script Python qui permet de générer des courriels à partir d'un fichier CSV contenant les paramètres de personnalisation.
Les détails de ce programme sont présentés dans mon billet Envoi de courriels massifs avec Python
Organisation d'un programme politique bilingue
- Les données sont consignées dans des documents Markdown simple:
- Les métadonnées (titre, numéro et étiquettes) sont dans une entête YAML
- Le contenu de la proposition est écrit dans le corps du document
- Un dictionnaire d'étiquettes permet d'uniformiser les étiquettes entre les versions françaises et anglaises
- L'ensemble des sources est conservée dans un dépôt git, ce qui permet de faire un suivi des versions dans le futur.
- Les pages web sont créées en convertissant le contenu des fichiers Markdown en JSON avec le package Node.JS m2j.
#!/bin/bash
for p in source/articles/*.md
do
filename=$(basename $p)
parallel --semaphore -j+0 m2j "$p" -c -o release/${filename%.*}.json
done
- Puis en convertissant le corps du document en HTML à l'aide du package python markdown.
proposition = json.loads(open("../../release/p"+str(numero_proposition)+".json").read())
full_html = markdown.markdown(proposition['p'+str(numero_proposition)]['content'],output_format='html5')
- Le même fichier initial permet de créer des pages web de façon automatisée en interaction avec l'API de notre système de gestion de contenu ainsi qu'un document imprimable en PDF
#!/bin/bash
for p in source/articles/*.md
do
filename=$(basename $p)
echo $p
pandoc -f markdown -t latex -o release/${filename}.tex $p
done
- La mise à jour des différents documents est grandement simplifiée avec plusieurs scripts Bash et Python
#!/bin/bash
last_num=$(ls p* | tail -n 1 | sed -n -re 's/^p0*([1-9][0-9]*)\.md$/\1/p')
let "current_num=${last_num}+1"
echo "Numéro courant: ${current_num}"
padded_num=$(printf "%04g" ${current_num})
echo -e "---" > "p${padded_num}.md"
echo -e "numero: ${current_num}" >> "p${padded_num}.md"
echo -e "title: \"\"" >> "p${padded_num}.md"
echo -e "tags:\n\s\s- $1\n\s\s- $2\n\s\s- " >> "p${padded_num}.md"
echo -e "---" >> "p${padded_num}.md"
Gestion de profils de candidats
- Une approche similaire à la gestion des pages du programme a été appliquée à la gestion des pages de candidats. Étant donné la possibilité de nombreux changement et imprévus, de pouvoir générer des pages standardisées à la volée a permis de pouvoir sauver beaucoup de temps au niveau de la maintenance du site web.
Comment faire beaucoup avec peu
L'équipe TI étant pas mal limitée à moi, un mélange de scripts et d'outils de collaboration tels que Google Docs ont permis de pouvoir mettre à jour les contenus webs assez facilement. Le maintien d'une qualité de données a cependant été difficile. Il est facile de casser un scripts qui lit un fichier lorsqu'on insère des caractères spéciaux ou on supprime un titre.
Détection de visages
La librairie OpenCV permet d'utiliser différents modèles de segmentation et d'identification d'objets. Notamment, on y retrouve quelques algorithmes de détection de visages, appelés Haar Feature-based Cascade Classifiers. Comme j'avais de nombreuses photos à cadrer afin de produire des publications web dans un format standardisées, j'ai décidé de tenter le coup avec cet outil. J'ai ainsi pu découvrir certaines de ses forces et de ses faiblesses.
Les algorithmes sont entrainés à détecter différents éléments composant un tout de façon hiérarchique. Par exemple, un visage est constitué de deux yeux, un nez et une bouche, sur lesquels on entraîne chacun un modèle prédictif. Ces trois modèles peuvent être combinés pour ensuite détecter un visage en spécifiant la position approximative et la séquence des composantes.
OpenCV permet d'utiliser directement des modèles pré-entrainés pour détecter des visages.
Voir la documentation pour plus de détails: Face Detection using Haar Cascades
Les modèles performent bien sur des photos prises en mode portrait, centrées avec un fond suffisamment uniforme. Il est aussi recommandé d'éviter les vêtements avec beaucoup de motifs. En alternant entre deux modèles, j'ai pu arriver à cadrer environ 90% des photographies reçues. Pour les 10% restants, quelques ajustements manuels et recentrage à l'aide du logiciel GIMP ont permis d'ensuite les passer à l'algorithme avec un succès relatif. Ça marche ou ça ne marche pas. Mais ça peut vous retourner une oreille ou un noeud de cravate au lieu d'un visage.
Production d'un atlas
Créer un atlas à partir de couches d'information et d'une couche de polygones à l'aide du logiciel QGIS.
Paramétrer chaque page de l'atlas depuis une couche avec différent composants: carte, tableau
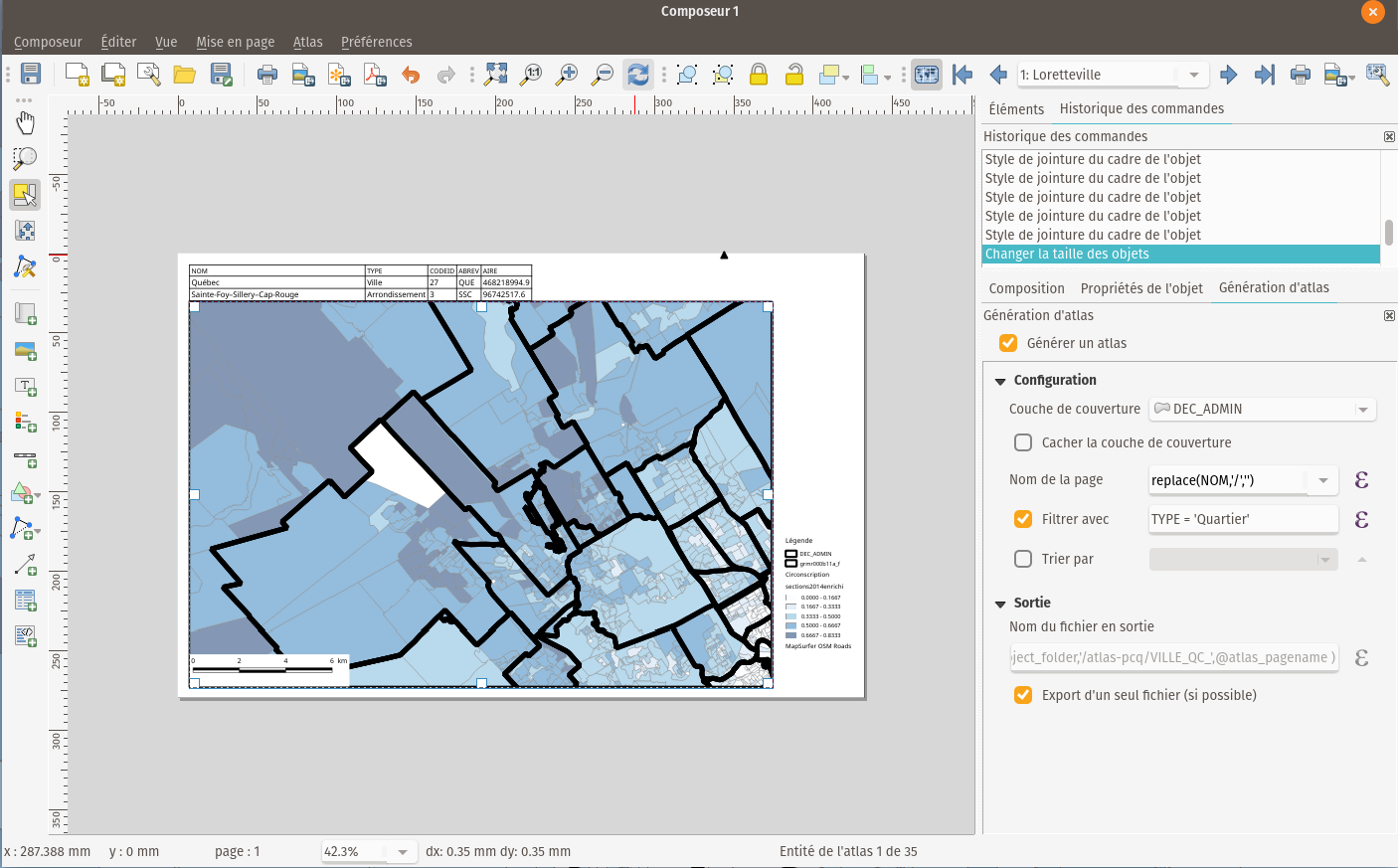
Pour plus de détails, on peut consulter l'article suivant: How to Create QGIS Atlas Mapbooks
Traduction
Pour faire la traduction, j'ai utilisé en majeure partie le site web Bing Translator