16 KiB
| title | author |
|---|---|
| Nettoyage et intégration de données hétéroclites. | francois@francoispelletier.org |
Le projet
Le projet "cloche" est né suite au dépôt du projet de loi 61 au printemps 2020. Il cherche à établir un diagnostic de notre système de santé pour les personnes âgées et du système d'éducation à l'aide de données ouvertes, afin de suggérer les meilleurs endroits pour construire des nouvelles résidences et écoles.
Pourquoi : Développer de nouvelles compétences. Aider notre gouvernement qui en arrache.
Infrastructure
- Logiciels :
- Python
- PostgreSQL et PostGIS
- pgAdmin
- RStudio
- J'utilise des conteneurs Docker pour avoir une installation standardisée le plus possible.
- Les conteneurs sont assemblés avec docker-compose
Voici mon installation : docker-compose.yml
Acquisition des données
J'essaie autant que possible de télécharger les données de manière reproductible avec des scripts bash. Les données sont acquises depuis différents sites du gouvernement, des sites GitHub et aussi via des demandes d'accès à l'information.
Capacités des installations - Préparation des données
*Premier exemple *: Source : Capacités des installations
Premièrement, on télécharge les données
wget https://www.donneesquebec.ca/recherche/fr/dataset/e442a663-e069-4209-a4ba-7bd60f6c5fb4/resource/7038bb19-ad37-49ae-b2d0-aec844d41970/download/gouvernement-ouvert-20200702.csv \
--output-document=capacite_services_installation_20200702.csv
Puis, on les lit dans Python avec Pandas
capacite_services_installation_20200702 =\
pd.read_csv("/raw/donneesquebec/capacite_services_installation_20200702.csv")
Voici un exemple de données :
Code :
capacite_services_installation_20200702.iloc[0].to_dict()
Résultat :
{'RSS_Etablissement' : '01 - Bas-Saint-Laurent',
'RTS_Etablissement' : '011 - RTS du Bas-Saint-Laurent',
'Code_Etablissement_(Regroupes_inclus_dans_CISSS/CIUSSS)' : 11045119.0,
'Nom_Etablissement_(Regroupes_inclus_dans_CISSS/CIUSSS)' : 'CISSS DU BAS-SAINT-LAURENT',
'Code_Etablissement' : 11045119,
'Nom_Etablissement' : 'CISSS DU BAS-SAINT-LAURENT',
'Statut' : 'Public',
'Mode_financement' : 'Budget',
'Territoire_CLSC_Installation' : '01161 - La Mitis',
'Code_Installation' : 51216281,
'Nom_Installation' : 'SERVICES PROFESSIONNELS - MRC MITIS',
'MCT-Capacite/Service_Installation' : 'CRDI ',
'Unite_mesure_Installation' : "Place(s) en centre d'activités de jour",
'Capacite(C)_Service (S)_Installation' : 'C',
'Capacite_Installation' : '20',
'Date_extraction' : 'Produit le 2020-07-02'}
Capacités des installations - séparer une colonne avec une expression régulière
On remarquera que le champ RSS_Etablissement contient deux données : le code numérique de la région administrative et le nom de la région.
Nous allons préférer utiliser un identifiant numérique, alors on sépare le champ en deux colonnes en utilisant la fonction extract qui prend en argument une expression régulière :
rss_mod = capacite_services_installation_20200702['RSS_Etablissement']\
.str\
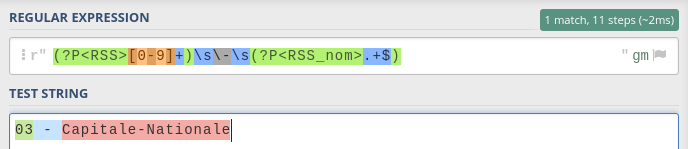
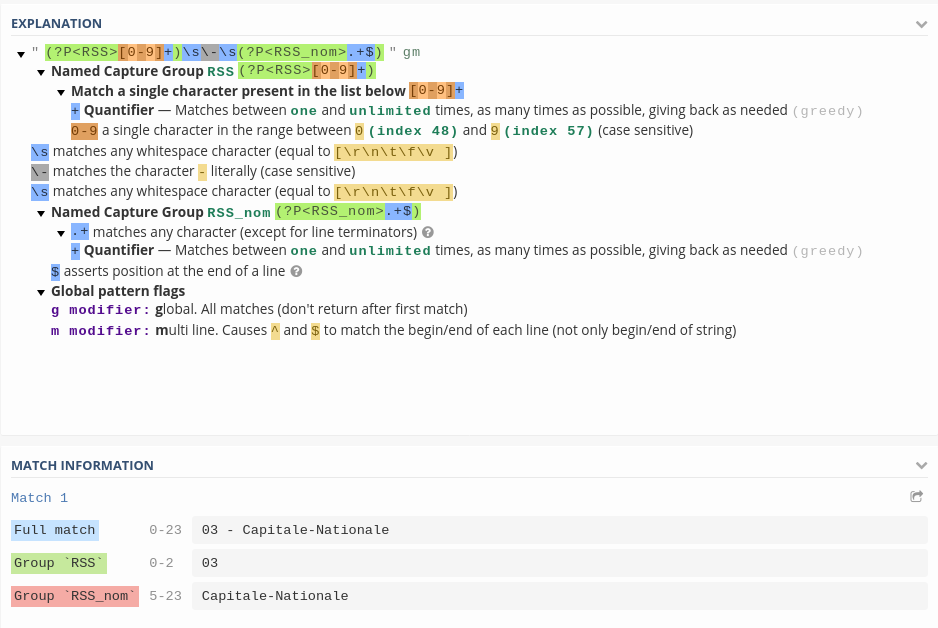
.extract(r'(?P<RSS>[0-9]+)\s\-\s(?P<RSS_nom>.+$)')
Remarquez la syntaxe ?P<> qui débute un groupe de capture délimité par des parenthèses. Ceci permet de nommer les groupes, qui deviendront des colonnes d'un DataFrame.
*Conseil *: Pour avoir le détail d'une expression régulière, j'utilise le site regex101.com
On remplace ensuite les valeurs manquantes pour éviter les erreurs :
rss_mod.fillna(0, inplace=True)
On importe ces nouvelles colonnes dans le DataFrame principal
capacite_services_installation_20200702['RSS'] = rss_mod['RSS'].astype(int)
capacite_services_installation_20200702['RSS_nom'] = rss_mod['RSS_nom']
On supprime la colonne originale
del capacite_services_installation_20200702['RSS_Etablissement']
Capacités des installations - nettoyer une colonne
La colonne "Date extration" contient une date, précédée de la chaine "Produit le ".
Nous souhaitons convertir ce champ en date.
On supprime la chaine de caractère superflue avec la méthode replace, puis on convertit la colonne au format date avec la fonction to_datetime de Pandas, avec les paramètres par défaut, puisque la date est déjà en format ISO 8601.
capacite_services_installation_20200702['Date_extraction']=\
pd.to_datetime(capacite_services_installation_20200702['Date_extraction']\
.str\
.replace(r'Produit le ',''))
*Conseil *: Convertissez toujours vos dates en ISO 8601. Vous allez apprendre à aimer les dates !
Capacités des installations - Caractère vers numérique
Vous retrouverez parfois des manières originales de marquer les valeurs manquantes. Souvent, celles-ci auront pour conséquence qu'une colonne numérique sera lue comme une colonne caractère. Vous voulez donc la convertir en valeur numérique.
capacite_services_installation_20200702['Capacite_Installation']=\
capacite_services_installation_20200702['Capacite_Installation']\
.str\
.replace('n.a.','0')\
.astype(int)
Capacités des installations - Chargement des données
Comme j'écris dans une base de données PostgreSQL, j'utilise le module psycopg2.
Je me suis fait quelques fonctions pour aider
J'ai aussi utilisé une technique d'importation rapide qui utilise le module de bas niveau StringIO, emprunté de la page GitHub de Naysan Saran. Merci !
Pour charger les données dans une table de la base de données PostgreSQL, je crée le DDL à la main
TODO : générer le string create_statement automatiquement !
ps_table.table_if_not_exists(conn=conn,
table="msss_gouv_qc_ca.capacite_services_installation",
create_statement="""
id integer not null,
Code_Etablissement_Reg integer,
Nom_Etablissement_Reg text,
Code_Etablissement integer,
Nom_Etablissement text,
Statut text,
Mode_financement text,
Code_Installation integer,
Nom_Installation text,
MCT_Capacite_Service text,
Unite_mesure_Installation text,
Capacite_Service text,
Capacite_Installation integer,
Date_extraction date,
RSS integer,
RSS_nom text,
RTS integer,
RTS_nom text,
Territoire_CLSC integer,
Territoire_CLSC_nom text
""")
Ensuite, je charge les données dans la table que j'ai créée
cfs.copy_from_stringio(conn=conn,
df=capacite_services_installation_20200702,
table="msss_gouv_qc_ca.capacite_services_installation")
Effectif du réseau de la santé - Préparation des données
*Second exemple *: Source : Portrait des effectifs du réseau de la santé et des services sociaux
Premièrement, on télécharge les données
wget https://www.donneesquebec.ca/recherche/fr/dataset/25dabc10-e61a-491c-a0de-98b4d788b4d2/resource/36a2b8b4-899c-408d-92bb-5ae9383eb89c/download/a---donneesparcategoriesetsous-categoriesdepersonnelconcernant.csv \
--output-document=a_categorie_ss_personnel_etc_emploi.csv
Puis, on les lit dans Python avec Pandas, en utilisant la colonne NUMEROTATION comme index.
a_categorie_ss_personnel_etc_emploi =\
pd.read_csv("/raw/msss_gouv_qc_ca/a_categorie_ss_personnel_etc_emploi.csv",
index_col="NUMEROTATION")
Exemple de donnes :
Code :
a_categorie_ss_personnel_etc_emploi.iloc[0].to_dict()
Résultat :
{'VARIABLES' : "Nombre de personnes en emploi au 31 mars de l'année",
'CATEGORIE_PERSONNEL' : '11 - Infirmière',
'2019_TOTAL_EFFECTIF' : '31 296',
'2018_TOTAL_EFFECTIF' : '31 778',
'2017_TOTAL_EFFECTIF' : '32 310',
'2016_TOTAL_EFFECTIF' : '33 434',
'2015_TOTAL_EFFECTIF' : '33 805',
'2014_TOTAL_EFFECTIF' : '35 011',
'2013_TOTAL_EFFECTIF' : '35 114',
'2012_TOTAL_EFFECTIF' : '35 275',
'2011_TOTAL_EFFECTIF' : '35 670',
'2010_TOTAL_EFFECTIF' : '36 087',
'TITRE_RAPPORT' : 'Données par catégories et sous-catégories de personnel concernant',
'DATE_PRODUCTION' : '2019-12-01',
'SOURCE' : 'Banque de données sur les cadres et salariés du réseau de la santé et des services sociaux (R25)',
'PRODUIT_PAR' : 'Direction générale du personnel réseau et ministériel (DGPRM) du MSSS'}
Effectif du réseau de la santé - Correction d'un nom de colonne
On doit corriger le nom d'une colonne qui contient un tiret
a_categorie_ss_personnel_etc_emploi = a_categorie_ss_personnel_etc_emploi\
.rename(columns={"CATEGORIE_SOUS-CATEGIE_PERSONNEL":"CATEGORIE_PERSONNEL"})
Effectif du réseau de la santé - Format large vers format long
Les données des effectifs sont disposées selon le format "large" dans le fichier CSV, on désire donc les ramener sur le format "long" pour faciliter les traitements futurs en ayant des données normalisées.
*Conseil *: La forme normale de Boyce-Codd est la représentation de données la plus courante dans les bases de données relationnelles. C'est un des concepts les plus importants en informatique qui a permis l'essor des bases de données et de la science des données. Vous devriez toujours chercher à stocker vos données sous cette forme.
a_categorie_ss_personnel_etc_emploi_m = pd.melt(frame=a_categorie_ss_personnel_etc_emploi,
id_vars=['VARIABLES',
'CATEGORIE_PERSONNEL',
'TITRE_RAPPORT',
'DATE_PRODUCTION',
'SOURCE',
'PRODUIT_PAR'],
value_vars=['2019_TOTAL_EFFECTIF',
'2018_TOTAL_EFFECTIF',
'2017_TOTAL_EFFECTIF',
'2016_TOTAL_EFFECTIF',
'2015_TOTAL_EFFECTIF',
'2014_TOTAL_EFFECTIF',
'2013_TOTAL_EFFECTIF',
'2012_TOTAL_EFFECTIF',
'2011_TOTAL_EFFECTIF',
'2010_TOTAL_EFFECTIF'],
var_name='ANNEE',
value_name='TOTAL_EFFECTIF'
)
On extrait ensuite l'année de la colonne ANNEE:
a_categorie_ss_personnel_etc_emploi_m['ANNEE']=a_categorie_ss_personnel_etc_emploi_m['ANNEE']\
.str\
.extract(r'(?P<annee>[0-9]+)_TOTAL_EFFECTIF')\
.astype(int)
Éducation - Indices de défavorisation
Source : Éducation - Indices de défavorisation
Téléchargement des données :
wget http://www.education.gouv.qc.ca/fileadmin/site_web/documents/PSG/statistiques_info_decisionnelle/Indices-defavorisation-2018-2019.xlsx \
--output-document=Indices-defavorisation-2018-2019.xlsx
Nous avons ici affaire à des chiffriers Excel qui contiennent des données qui ne sont pas directement exploitables. Nous allons donc faire du "Excel Mining" avec le module xlrd (Site web).
La grosse fonction qui fait tout !
TODO : Refactoriser en plusieurs petites fonctions
def indices_ecoles(loc,periode) :
wb = xlrd.open_workbook(loc)
# Décompte du nombre de feuilles
nb_sheets = wb.nsheets
# Liste pour contenir chacune des écoles
liste_ecoles = []
# Boucle sur chacune des feuilles (commissions scolaires)
for sheet_no in range(nb_sheets):
sheet = wb.sheet_by_index(sheet_no)
# Nous faisons l'extraction de certaines métadonnées
meta = {
'periode':periode,
'numero_cs':sheet.cell_value(1, 0),
'nom_cs':sheet.cell_value(1, 1)
}
# On itère ensuite sur chaque ligne pour identifier
# les sections avec les écoles primaires et secondaires
for i in range(sheet.nrows) :
if sheet.cell_value(i, 1) == 'Écoles secondaires':
type_ecole = ['secondaire']
if sheet.cell_value(i, 1) == 'Écoles primaires':
type_ecole = ['primaire']
# Le code à 6 chiffres est un code d'école
res = re.search(r'\d{6}', str(sheet.cell_value(i, 0)))
if res != None :
if sheet.cell_value(i, 0) != meta['numero_cs']:
all_values = list(meta.values())+type_ecole+sheet.row_values(i)
all_values = [str(x).strip() for x in all_values]
liste_ecoles.append(all_values)
df_ecoles = pandas.DataFrame(liste_ecoles,
columns=['periode',
'numero_cs',
'nom_cs',
'type_ecole',
'code_ecole',
'nom_ecole',
'indice_seuil_faible_revenu',
'rang_decile_sfr',
'indice_milieu_socio_econo',
'rang_decile_imse',
'nb_eleves'])
df_ecoles[['numero_cs','code_ecole']] = df_ecoles[['numero_cs','code_ecole']].applymap(lambda x : x.replace(r'.0',''))
return df_ecoles
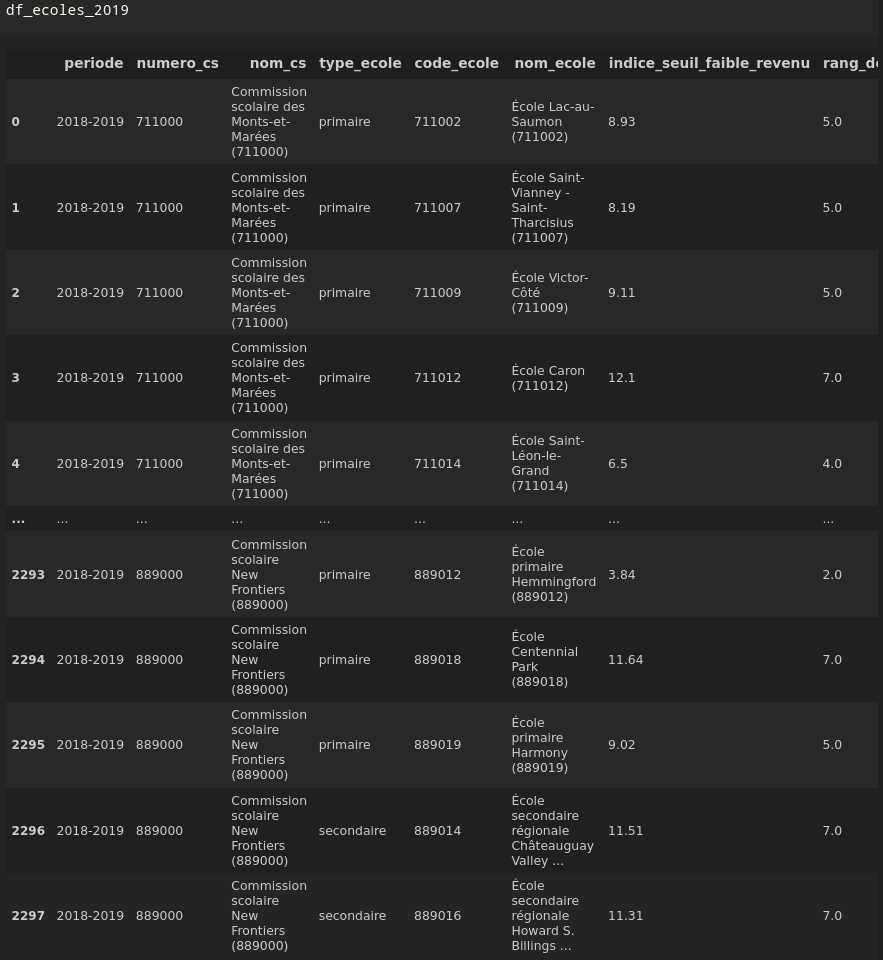
On appelle la fonction
df_ecoles_2019 = indices_ecoles(loc[2],'2018-2019')
Et nous avons des données nettoyées !
Pour les curieux
J'ai fait un web scraping de la base de données K10 du MSSS : Registre des résidences privées pour aînés avec scrapy.
Conclusion
Bientôt ...
- Extraction OCR de fichiers Excel imprimés, faxés puis numérisés (AKA demande d'accès à l'information) avec le module de vision par ordinateur OpenCV et Tesseract OCR
- Des statistiques descriptives
- Des modèles
Suivez mon projet sur ma page Gitea